
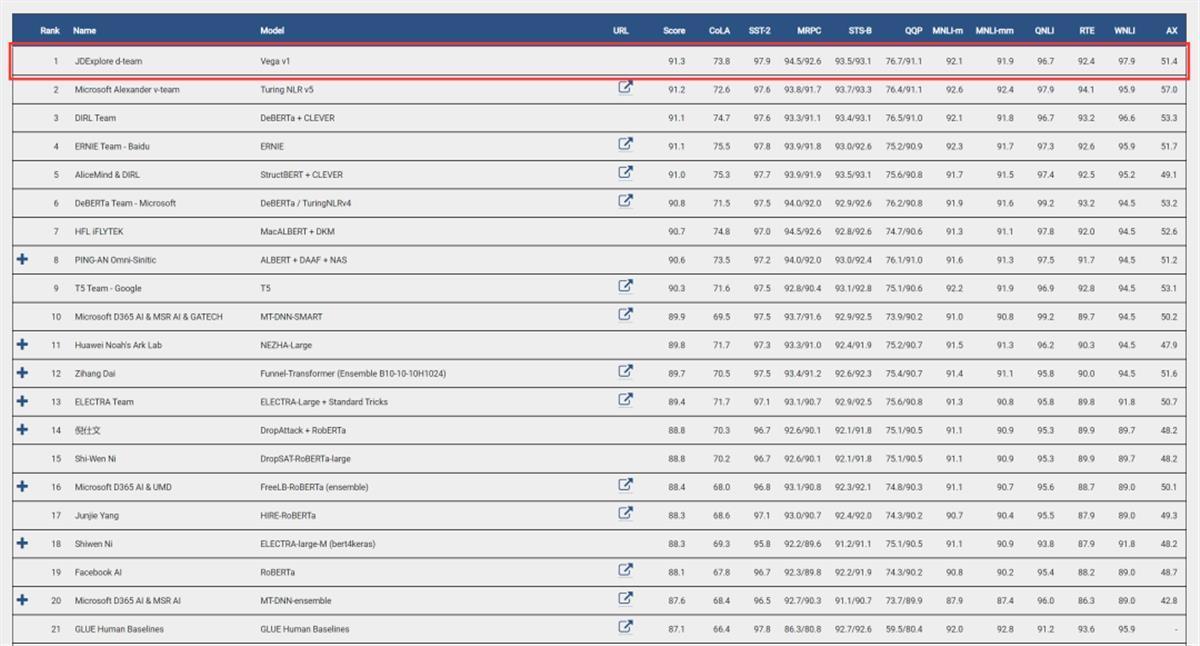
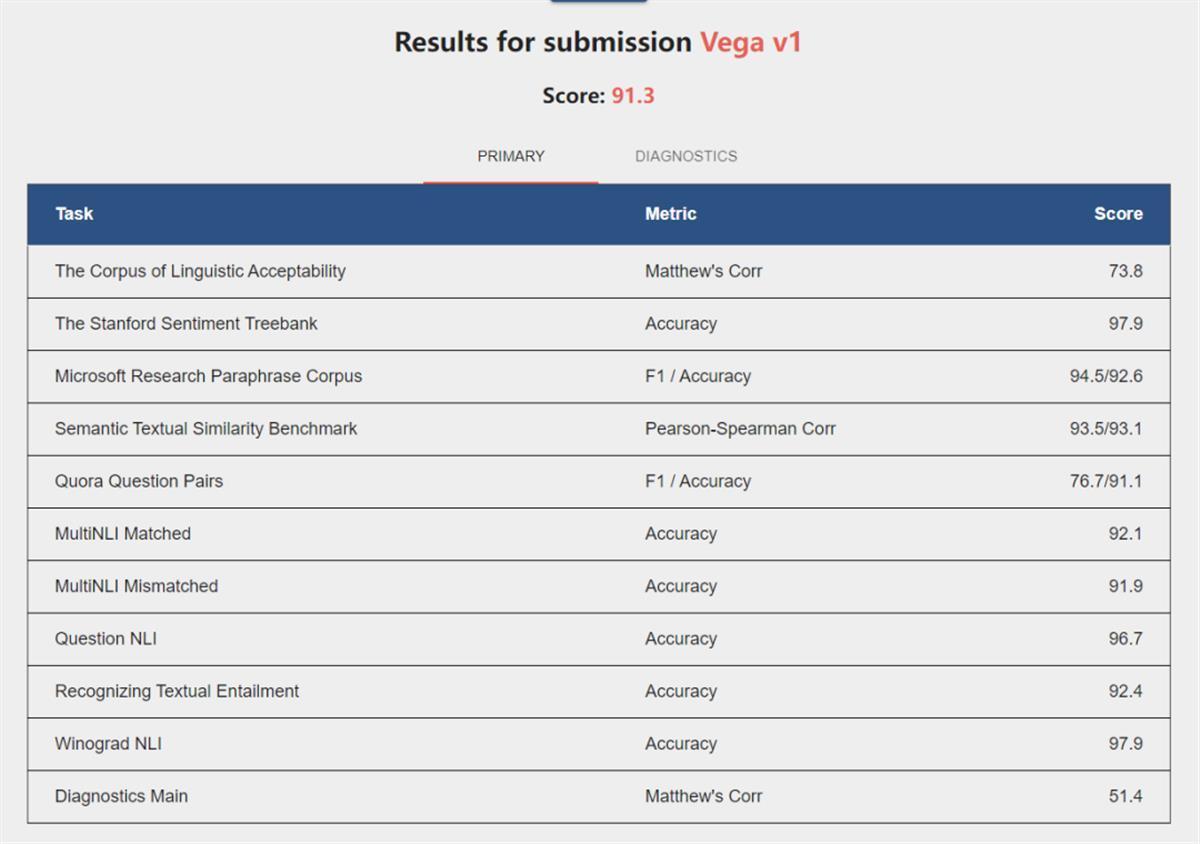
4月27日,湖北日报全媒记者从武汉大学获悉,在全球自然语言处理领域权威榜单GLUE中,武汉大学-京东可信人工智能联合研究中心共同提出的织女模型,以总平均分91.3分荣登榜首,刷新了自然语言理解技术世界纪录。
记者了解到,织女模型除了总平均分第一,也首次在这两个充满挑战的任务上超过了人类测试结果,表明织女模型将预训练模型的智能水平提升到了新的高度。未来,研究团队还将考虑融合可信人工智能等技术,对织女模型进行全面升级,使其不仅具有强大的文本理解能力,还能具备可解释性、保护隐私、公平性等重要属性。

“织女星”大放异彩
通用语言理解评估标准(GLUE)榜单,由纽约大学、华盛顿大学、谷歌DeepMind等机构联合推出,被认为是衡量自然语言处理预训练技术水平的重要指标之一。在日前公布的GLUE榜单中,由武汉大学-京东可信人工智能联合研究中心共同提出的超大参数规模的自然语言处理模型“织女模型Vega v1”,以91.3的高分超越了同场竞技的微软、Facebook、斯坦福大学等企业和高校团队,充分证明了“织女模型”在人工智能技术上的领先地位。

“织女”这个带有神秘和浪漫色彩的名字,源自于京东探索研究院的超大规模计算集群——天琴α,正是在它的支持下,才能够实现如此珍贵的大规模训练。而“织女座”是“天琴α”的别称,是天琴星座中最亮的恒星,团队希望织女模型能够成为预训练模型中最特别的存在。
专家介绍,织女模型作为通用的语言模型,能够适用于多种自然语言处理任务,在未来有非常广泛的应用场景,例如智能问答、对话机器人、语法纠错、自动驾驶等。如果采用模型压缩、剪枝、蒸馏等方式,将织女模型轻量化,得到一个参数量更小的模型,并将其部署在智能终端中,将使人们的日常生活更加便利。
除了模型本身的强大能力,研究团队还采取了许多相匹配的高效微调策略,在下游具体的自然语言处理任务的少量标注样本下,对模型进行高效的参数更新,有效提升了织女模型的准确性。
智能水平突破新高度
人工智能中的任务普遍存在泛化性不足的问题,即针对每个AI任务,经常需要使用相关的数据集训练特定的模型。同样的特定模型,在当前任务下表现出色,但在其他任务上的表现可能就不尽如人意。
为了解决这个难题,拓宽人工智能的通用性,越来越多的人工智能采用了“通用预训练模型”。通过大规模数据集训练一个通用的模型,并在特定任务上微调,就能取得很好的效果,有效解决模型泛化性不足的难题。
专家表示,织女模型作为一个大规模预训练语言模型,在各种下游任务上也都取得了不错的效果。相比于提交到GLUE榜单中的其他模型,它在多个重要的预训练技术上实现了突破:如高效节能的并行化训练框架以及数据利用方法、数十亿参数量的创新模型架构、更好的自监督预训练目标以及让模型根据单词、短语、短句等不同粒度学习整个句子的表征,实现多粒度句子级表征等,这使得模型本身更具竞争力。
GLUE榜单中共涵盖自然语言推断、语义相似度匹配、问答等9大NLP任务,在榜单设立初期提供了每个任务的人类测试结果,代表了各个任务的人类智能水平。随着预训练模型的不断研究,预训练模型已经能够在GLUE中多个任务上超过人类测试结果,但唯独在情感分析和指代消解任务上,迟迟没有模型能够超过人类结果。而织女模型不仅在GLUE榜单上以总平均分第一登顶榜首,也首次在这两个充满挑战的任务上超过了人类测试结果,表明了织女模型将预训练模型的智能水平提升到新的高度。
“织女星”背后的造梦者
作为由武汉大学人工智能研究院、计算机学院与京东联合成立的科研机构,武汉大学-京东可信人工智能联合研究中心自2021年成立以来,已累计发表数十篇高水平研究论文,并在ICCV2021多目标跟踪竞赛的深度+视频大赛与全球自然语言处理领域顶级测试GLUE大赛中,均取得了世界第一的佳绩。
在模型训练与比赛的过程中,团队也遇到了诸多困难,如缺乏大规模模型训练经验,很多东西都得从头学习;模型训练需要非常多的计算资源,如何高效充分利用这些资源是一个大的挑战。
面对困难,团队一起分析问题,调试代码,探讨如何提升效果。在模型训练的过程中,经常调试代码到凌晨……正是这些努力,让织女模型不断优化、不断进步。
团队核心成员钟起煌博士认为,学习和科研都需要沉得住气,潜心研究,“选一个方向,定一个时间,剩下的只管努力与坚持,时间会给我们最后的答案。”正因如此,他们在人工智能研究领域才能攻坚克难,取得卓越成绩,就像织女星一样,在天空中闪耀璀璨光芒。
据了解,未来,该团队还将考虑融合可信人工智能等技术对织女模型进行全面升级,使其不仅具有强大的文本理解能力,还能具备可解释性、保护隐私、公平性等重要属性。
(湖北日报全媒记者田佩雯 通讯员张华、关彤)
